Humans In the (AI) Loop


I’m sure that by now, many of you have used ChatGPT and seen how incredible it is. If not, I highly recommend you stop what you’re doing and give it a try.
Last week, I found an interesting article on how OpenAI (the firm that developed ChatGPT) used workers in Kenya to train the model at a very low cost:
“A new investigation from Time claims OpenAI, the upstart darling behind the powerful new generative AI chatbot ChatGPT, relied on outsourced Kenyan laborers, many paid under $2 per hour, to sift through some of the internet’s darkest corners in order to create an additional AI filter system that would be embedded in ChatGPT to scan it for signs of humanity’s worst horrors. That detector would then essentially filter ChatGPT, which has so far gained over 1 million users, palatable for mass audiences. Additionally, the detector would reportedly help remove toxic entries from the large datasets used to train ChatGPT.”
According to the article, these workers earned between $1.32 – $2 per hour.
“Overall, the teams of workers were reportedly tasked with reading and labeling around 150-250 passages of text in a nine hour shift. Though the workers were granted the ability to see wellness counselors, they nonetheless told Time they felt mentally scarred by the work. Sama disputed those figures, telling Time the workers were only expected to label 70 passages per shift.”
So I asked ChatGPT to help me write this article. Initially, I was a bit aggressive:

So maybe I shouldn’t have used the term “exploit.”
Still no confession.
ChatGPT is only part of the tools that OpenAI is offering, so I asked Playground (which is another one) the same question, and the answer was surprising:

So… ChatGPT is “not aware” of what Playground is aware of (the red marks are from Grammarly, and I kept them to maintain the original answer).
While we’re all excited about AI and ChatGPT, and how it feels more like a conversation with a knowledgeable human rather than a chatbot, the reality is that there’s significant labor and human operations behind it. I’m not planning on directing this post toward the question of exploitation —the Kenyan workers were paid double the median income in Kenya— but there are questions on how these workers are treated and how to help their mental health, given that many texts and images can be quite traumatizing (at least for those who do content moderation). This is not unique to OpenAI. Meta has also dealt with lawsuits over claims of exploiting workers in Kenya.
My primary goal is not to litigate these claims, but to explore the interaction between operations (specifically gig work) and AI.
One of AI’s primary goals is to reduce the marginal cost of tasks previously done by humans and, potentially over time increase the quality and consistency of these tasks, allowing humans to focus on being creative and innovative rather than being repetitive. But the point I’m trying to make is that there’s no insignificant variable cost (or at least, non-zero marginal cost) to do that.
Most machine models need humans to provide the ground truth so that they can be trained. Labeling, training, classifying, moderating, and edge casing are all things humans need to do.
I’m sure there are other classifications on the ways humans are involved with behind-the-scenes work for AI, but I will look at the following time frames:
Time before the AI algorithm interacts with a real environment.
Time during the interaction.
During the interaction, we will also distinguish between medium time response (within 30–60 seconds) and real-time response (immediate).
Before: Labeling and Training
Scale.AI is one of the main names that powers a lot of the data labeling of systems we use. Its founder, Alexandr Wang, started with the autonomous vehicle industry by creating a lidar labeling tool. As the company expanded to other industries, it started offering a more comprehensive solution to the entire process of AI development, from data annotation to data debugging, and model improvements. According to different sources, Scale AI works with various industries: Brex, OpenAI, and the US Army, to name a few.
The firm recently expanded, offering more “self-service” solutions and allowing smaller researchers to use the platform. When a researcher or developer wants to label a dataset using machine learning, they create a set of instructions for the task. These instructions can be different tasks, such as identifying objects in an image, adding annotations to an audio clip, or classifying the sentiment of a review as positive or negative.
How many people are involved in this operation?
“Scale AI has a labor source of more than 100,000 labelers, according to Porter. The company determines whether a task requires expert labelers and helps avoid shortcomings found in some popular labeling processes, like consensus voting. In consensus voting, a labeling task might be sent to five people and the majority result is taken as the valid label. The problem is that the majority can be wrong. For example, if the task requires someone to differentiate between a crow and grackle, four out of five labelers might mistake a grackle for the more commonly known crow. So Scale AI brings in what it calls ‘expert spotters.’ It then tries to automate the labeling process with ML.”
Up until 2022, the firm has raised $600M at a $7.3B valuation. It’s a big market and Labelbox, Hive, Cloudfactory, and Samasource (involved with Meta in the article I mentioned above) are other firms involved during this training stage.
Dealing with Edge Cases
While the work described above is necessary, it happens before the actual interaction with the users.
I’ve written about automation before and explained that when it comes to specialized jobs, automation works well. But when tasks are too general and more flexibility is needed, automation usually “fails” to deliver. For example, the ability to pick and pack, while seemingly simple, is quite complex — items vary significantly in terms of the force needed to pick them (but not break them), and recognizing items is not easy, if they’re not positioned the exact same way every time.
For example, Sparrow, Amazon’s new pick-and-pack robot, identifies only about 65% of the company’s product inventory. What about the rest?
Allowing robots to operate in such environments may require delegating other cases in real time to humans. The problem is we can’t know, in advance, which cases will require human intervention. So here is a set of solutions that are more real-time (I call them almost real-time since they are not always instantaneous). Spark.ai is one of the main players offering these solutions:
“SparkAI combines people and technology to resolve AI edge cases, false positives, and other exceptions encountered live in production, so you can launch & scale automation products faster than ever.”
I love this graph from their website:
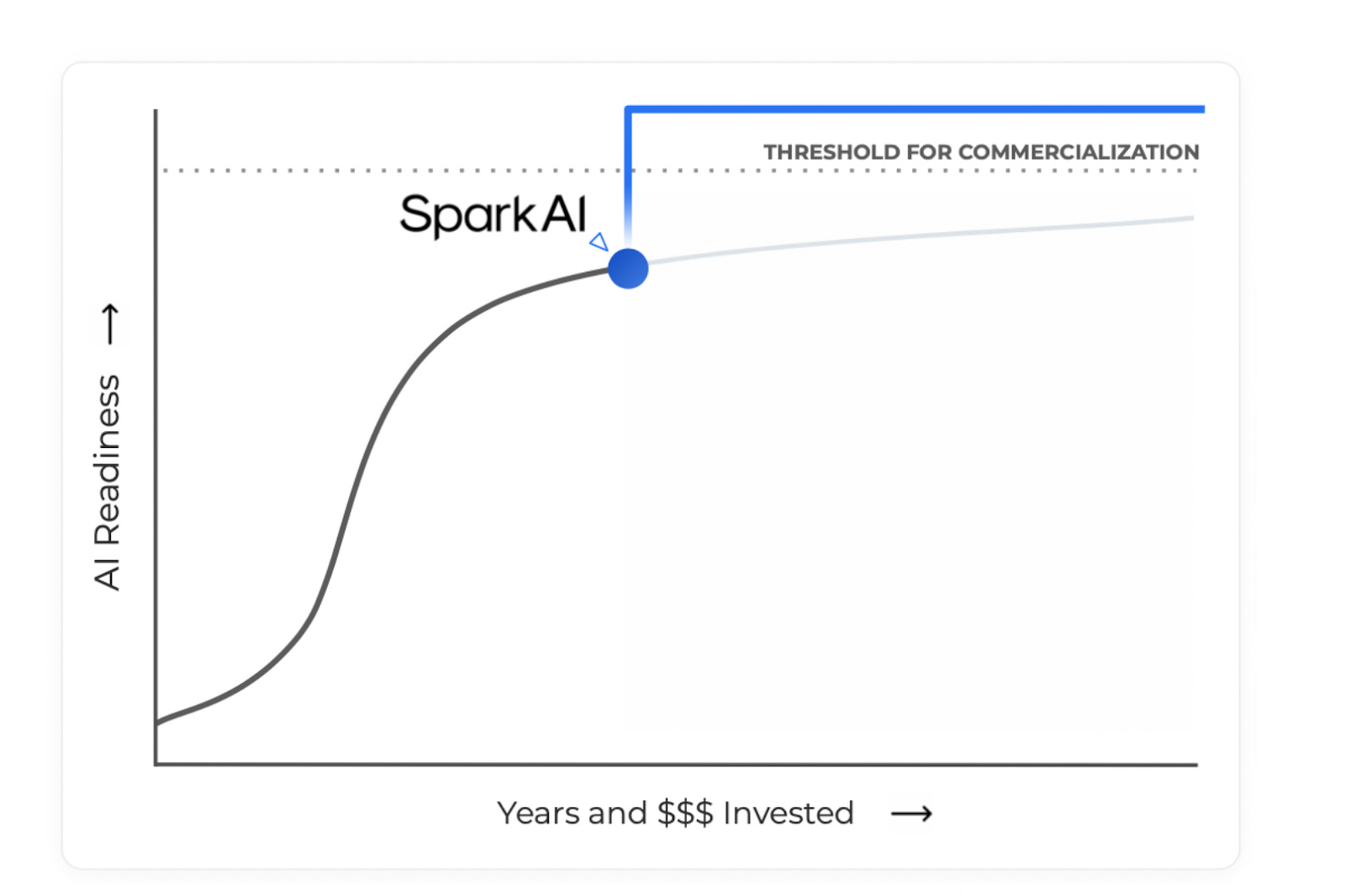
For many jobs, the future is almost fully automated, but we’re not there yet. Rather than wait until we pass this threshold, let’s add a human in the loop, in the most efficient manner possible.
How? With a simple API that allows Spark AI to handle these edge cases fast. How fast? Within 30 seconds —enough for delivery robots, agriculture, and even pick and pack robots.
Here is how it works (the photo is courtesy of Spark.ai).

Real-Time
Why am I reluctant to refer to what I discussed above as real-time? There are situations where you need someone to take over the algorithm, immediately:
“Magzimof is the cofounder and CEO of Phantom Auto, a startup betting that [...] long distance driving will be crucial to anyone looking to deploy (mostly) autonomous vehicles. ‘We’re not aiming to replace AVs,’ he says. He wants to provide the ability to have a human briefly take control of the car whenever the robot encounters what engineering types call ‘edge cases.’ It could be a construction zone, or a cop using hand signals to direct traffic, or the gaping maw of a sinkhole. Anything weird and complex enough to upset a computer system that’s happiest when everyone follows the rules.”
According to the firm, this works for complex situations but not for emergencies (where the person in the car should take control).
And this is where regulators are already intervening:
“California’s DMV has proposed rules that would allow human-free cars onto public roads, but would require that their operators maintain a way to communicate with the vehicle from afar. Florida’s self-driving regulations require the vehicle’s operator—who doesn’t have to be inside the thing—retain the ability to control, or at least stop, the car.”
What’s the tradeoff?
Scalability, speed, and safety… and, as usual… cost.
Let’s start with the latter, the real-time solution:
“The average autonomous vehicle operator salary in the USA is $46,800 per year or $22.50 per hour. Entry level positions start at $42,900 per year while most experienced workers make up to $56,550 per year.”
Some firms are already thinking about the cost implication of these remote operations, given that the salaries are only about half of what the average truck driver in the US makes. The solution?
“Swedish startup Einride, engaged in autonomous electric vehicles, has demonstrated for the very first time its one operator, multiple vehicle capability at a customer site…. The innovation here is that a single operator can control both vehicles remotely, if required. The number of vehicles per single operator is expected to increase to several or even up to 10 ultimately.”
But this is for the extreme real-time teleoperator. How much does a data labeler make?

This is clearly a situation where the average mark isn’t a good indicator and is actually skewed by the right most values (I’m not even sure it’s correct). A more useful statistic says 51% of the jobs are between 30K and 40K, but you handle many more tasks.
Let’s do some back-of-envelope math: 150-250 paragraphs per 9 hours of work, in the case of OpenAI. If the wage is 35K, equivalent to an hourly rate of $16, this means that if data labelers handle 22 paragraphs per hour (again, on average), that’s 70 cents per task. If the pay is only $2 per hour, it’s only 10 cents per task (but with a massive volume of tasks).
OpenAI used 45TB of text to train GPT-3. If an average Tweet is 300 Bytes (as a proxy for a paragraph), it costs $15B (if my math is correct) to label all this data. I know. I know. The world is more complex than this.
And this doesn’t include hiring, testing, or validating the worker.
So definitely a low cost per unit of analysis, but not that low when you realize how much information needs to be analyzed —definitely not zero marginal cost and may never be.
In situations where context is important, where the rate of edge cases is not decreasing, the need for humans will only increase. The question is whether these data labelers will be the coal miners of the future, creating an even bigger divide between those using the models and those training the models. As an extensive user of these models, I am not sure I’ve fully paid attention to the possible implications and the human sides involved.
My colleague Christian Terwiesch wrote a paper about an experiment he conducted asking ChatGPT to take the core operations management exam. ChatGPT got a B/B-.
I “asked” ChatGPT to take the exam from my elective course on Scaling Operations.
It failed!
It didn’t matter how many questions I asked and how many guidelines I offered; it kept generating platitudes and generalities that triggered a failing grade.
I guess that’s good. AI can do the basic core tasks, allowing us the choice of what we want to do instead of what we need to.
Getting an A- in OIDD 236 suddenly makes me feel much smarter than AI now 😂
Scale.AI - Up until 2022, the firm has raised $600M at a $7.3B valuation. Its just building tools to label data or tools for model tracking etc. Why does it have such a valuation?
Also, there are labeling shops in India, where the salaries are nowhere close to $30K per year. I am not sure where these labelers are located. Now, labeling english documents might require english trained and native speakers, but labeling data (images, objects, simple text) does not and that work is done in lower cost countries.
However, Humans in the Loop, particularly in the cheaper countries, for the work that its automating and removing people from it, might cause societal issues in the long run. Long haul truck drivers is not one of them, simply because there is a long standing shortage of those. How about "importing" those drivers from low cost countries, just like we import products?